
레디스의 레플리케이션과 메커니즘을 알아보는 시간
데이터 레플리케이션: 쓰기 작업이 있을 때마다 업데이트된 데이터를 다른 서버로 복제하는 것
위 방식을 통해 얻을 수 있는 것
- 서버 추가 및 리소스 확장하여 읽기 쿼리의 부하 관리
- 데이터 중복성을 통한 페일오버로 가용성 얻을 수 있음
7.1 레플리케이션 기능
단일 노드 방식은 장애나 네트워크 연결 문제, 시스템 충돌 같은 문제에 쉽게 영향을 받는다.
따러서 실제 운영에서는 다중 노드로 구성하여 가용성을 확보한다.
레디스는 여러 노드로 운영하기 위한 레플리케이션 기능을 제공하고 있다.
마스터-레플리카 모델에서는 지속적으로 마스터의 업데이트 내용을 여러 레플리카에 반영하는데, 이 방식은 RDBMS에서 사용하는 방식과 유사하다.
레플리케이션의 목적은 '읽기 작업 확장과 고가용성을 위한 중복성 확보'이다.
비동기 처리를 통한 구현
레디스 레플리케이션의 비동기 처리 방식은 아래와 같은 순서로 진행된다.
1. 마스터 노드: 데이터를 저장하고 쓰기 연산을 처리한다.
2. 슬레이브 노드: 마스터 노드의 데이터를 복제하여 백업 역할을 수행한다.
3. 비동기 복제: 마스터 노드는 데이터를 슬레이브 노드에 전송한 후, 슬레이브 노드의 응답을 기다리지 않고 다음 작업을 진행한다.
위 방식으로 처리 했을 경우의 특징에는 아래와 같은 것들이 있다.
데이터 정합성 문제: 비동기 방식의 특성상 마스터 노드와 슬레이브 노드 간에 데이터가 일시적으로 일치하지 않을 수 있다.
장점: 마스터 노드의 성능 저하를 방지하여, 시스템 전체의 처리량을 높일 수 있다.
단점: 데이터 유실 가능성이 존재하며, 마스터 노드 장애 시 슬레이브 노드로의 자동 페일오버가 어려울 수 있다.
주의: 데이터의 일관성이 중요하다면, 동기식 레플리케이션이나 다른 방법을 고려해야 한다.
레플리케이션을 사용할 때 레디스를 연결하는 방법
각 캐시 노드의 IP 주소나 엔드포인트를 레디스 클라이언트에서 직접 접근하거나 twemproxy와 같은 프록시를 활용해 여러 레플리카의 요청 라우팅 과정을 자동화 할 수 있다.
기본적으로 읽기 전용인 레플리카
레플리카를 추가하여 읽기 작업의 부하를 관리하는 방법이 있다. 레플리카에 직접 쓰기 작업을 수행할 수도 있지만, 문제가 발생할 수 있다. 여기서 문제는 실행 시간이 많이 소요되는 작업은 레플리카에 쓰기 작업을 활성화하여 임시 데이터를 저장해두고 여러 번 참조하도록 하는 유스케이스를 고려해 볼 수 있다.
레플리케이션 주의사항
레플리케이션 작업을 실행할 때 마스터에 영속성이 설정되어 있지 않은 경우, 엔진을 재실행하거나 종료하면 데이터 세트가 초기화된 상태로 실행된다. 그리고 레플리카도 초기화되기 때문에 주의가 필요하다.
7.2 레플리케이션을 시작할 때의 메커니즘
레플리케이션이 이루어지기까지의 과정은 아래와 같다.
1. 레플리카는 PSYNC 명령어로 마스터에 연결을 요청하며, 해당 시점까지 처리한 레플리케이션 ID와 오프셋을 전송한다.
2. 마스터는 요청받은 마스터의 레플리케이션 ID와 자신의 레플리케이션 ID가 일치하는지 확인하고, 오프셋이 레플리케이션 백로그의 버퍼에 있는지 확인한다.
3. 요청 받은 오프셋이 레플리케이션 백로그에 있는지에 따라 처리가 달라진다.
3-1. 레플리케이션 백로그에서 동기화가 가능한 경우: 요청된 오프셋이 레플리케이션 백로그에 있고, 레플리케이션 백로그에서 동기화가 가능한 경우에는 부분된기화를 실행한다.
3-2. 레플리케이션 백로그에서 동기화가 불가능한 경우 : 레플리케이션 중단 중에 마스터가 받은 쓰기 작업 요청의 크기가 버퍼 크기를 초과하여 부분 동기화가 불가능한 경우에는 전체 동기화를 실행한다.
동기화를 시작할 때의 메커니즘은 크게 전체 동기화, 부분 동기화가 있다.
이렇게 구분하는 이유는 전체 동기화가 요청 처리에 미치는 영향이 크기 때문이다.
레플리케이션 메커니즘은 부분 동기화가 가능하면 이를 실행하고, 불가능하다면 전체 동기화가 수행된다.
전체 동기화
1. 레플리카가 마스터에 레플리케이션 시작을 요청한다.
2. 마스터는 BGSAVE 명렁어를 실행하여 프로세스를 포크 처리하고, 포크된 프로세스에서 메모리 스냅숏을 진행한다.
3. BGSAVE 처리가 완료된 후, RDB 파일을 레플리카로 전송한다. 그동안 마스터의 쓰기 작업은 레플리카의 클라이언트 출력 버퍼에 기록됩니다. 레플리카는 전송된 RDB 파일을 메모리로 불러온다.
4. RDB 파일 전송이 완료된 후, 레플리카의 클라이언트 출력 버퍼에 기록된 데이터를 레플리카로 전송한다.
5. 레플리카의 클라이언트 출력 버퍼에 쓰기 작업이 완료되면, 마스터의 쓰기 작업은 실시간으로 레플리카로 계속해서 전송된다.
전체 동기화를 진행 할 때 여러가지 케이스에 맞게 대응이 필요할텐데, 책에서는 아래 상황을 예시로 들고 있다.
1) 전체 동기화를 시작할 때의 세부사항
2) 여러 개의 레플리카가 있을 때의 동작
3) 레플리케이션 연결이 끊길 때의 동작
4) TTL이 설정된 키의 레플리케이션 동작
5) 디스크 없는 레플리케이션
6) 그 외 레플리케이션 최적화를 위한 확인 사항
각 케이스 마다 내부 설정 조정 등을 통해 해결 또는 개선이 가능하며, 자세한 내용은 생략하겠다.
위 예시 케이스만 알아도 면접이나 운영에서 적용하기 전 발생 가능한 부분들에 대하여 미리 생각/대응해 볼 수 있어서 좋을 것 같다.
부분 동기화
부분 동기화의 경우, 레플리케이션 연결이 끊어진 동안의 모든 쓰기 작업이 레플리케이션 백로그에서 레플리카로 전송된다.
레플리케이션의 마스터에는 레플리케이션 백로그라고 불리는 고정 길이의 리스트 위에 있는 메모리 영역이 있는데, 레플리케이션 연결이 끊어진 동안에는 이 백로그에서 쓰기 작업 정보를 일정 시간 동안 관리하게 된다.
백로그의 크기는 repl-backlog-size, 백로그의 시간은 repl-backlog-ttl 지시자로 설정 가능하다.
7.3 레플리케이션 동작 중 메커니즘
그 다음으로 알아볼 것은 마스터와 레플리카 간 연결이 어떻게 모니터링 진행 되는지에 대해서이다.
마스터는 기본적으로 10초 간격으로 모든 레플리카에 핑(ping)을 보낸다.
이 간격은 repl-ping-replica-period 지시자로 조정 가능하다.
카프카의 offest과 유사한 방식인 것 같은데, 레플리카는 매초 REPLCONF ACK<offset> 명령어를 사용하여 처리한 위치를 포함해 핑을 보내고, 마스터는 각 레플리카로부터 받은 마지막 핑의 시간을 기록한다.
이와 같은 메커니즘을 통해 레플리케이션 링크가 끊어졌을 때 레플리카가 타임아웃을 감지하기 전 문제를 확인할 수 있다.
추가적인 안전 장치로 마스터에서 레플리카로 보낼 뿐만 아니라 레플리카에서 마스터로도 핑을 보내도록 작동하고 있다.
유즈 케이스에 맞게 최소한으로 필요한 연결 상태 개수, 마스터와 레플리카 사이의 핑 타임아웃 등을 지시자로 설정하여 커스텀하게 사용 가능하다.
7.4 페일 오버
Failover
페일오버(Failover) 는 장애 조치 기능으로 시스템 장애 이벤트 발생 시 하나 이상의 예비 백업 시스템(노드) 로 자동 전환되는 것을 말한다.
즉, Fail(실패)를 Over(끝낸다) 는 의미로, 시스템 장애 시 준비되어있는 다른 시스템으로 대체되어 운영되는 것을 말한다.
스위치오버(Switch Over)와 대조되는 개념으로, 스위치오버는 시스템 장애 이벤트가 발생했을 경우 하나 이상의 백업 노드로 수동 전환되는 것을 말합니다.
페일오버와 스위치오버 둘 다 시스템이 전환된다는 개념은 같으나 페일오버는 자동, 스위치오버는 수동으로 구분하면 될 것 같다.
레디스는 마스터에 문제가 생기면, 자동으로 페일오버하는 기능이 기본적으로는 없다.
만약 마스터가 다운되었을 경우 새로운 마스터로 승격시킬 노드에서 REPLICAOF NO ONE 명령어를 수동으로 실행해야 한다.
관리형 서비스에서 레플리케이션 기능을 사용할 경우 앞서 언급한 명령어는 제한될 수 있고, 대신 자동 페일오버 기능이 제공될 수 있다.
따라서 레디스를 제공하는 서비스를 사용할 경우, 어떤 기능이 갖춰져 있는지 문서를 확인하는게 좋다.
7.5 레플리케이션 도입 방법
이 파트는 실제 마스터와 레플리카를 각 한 대씩 두고, 앞서 나왔던 것들을 실습해 보는 부분이다.
간단히 도커 컴포즈를 사용하여 단일 서버에 여러 레디스 인스턴스를 실행하는 컨테이너를 사용해 어떻게 동작하는지 확인하고 있다.
마스터와 레플리카 설정 파일은 각각 redis-master.conf, redis-replica.conf로 두고 레플리카 설정에서는 마스터의 IP 주소와 포트를 설정한다. 기본 포트는 6379 이다.
이때 레플리카는 마스터 정보 캐시가 없기 때문에 부분 동기화가 불가능하고, 전체 동기화만 수행한다.
마스터에서 RDB 파일을 가져와 이전 데이터를 삭제하고 메모리에 데이터를 저장하게 되는데, 이 과정이 로그에 표시된다.
레플리카에서 MONITOR 명령어를 실행하면 10초 마다 마스터에 PING 명령어가 전송되게 된다.
+ 레디스 센티널
마지막 부분에 언급되는 레디스 센티널은 모니터링, 알림, 자동 페일오버 등 레디스에 고가용성을 제공한다.
현재는 버전 2 사용을 권장하고 있다.
레디스 센티널은 아래 그림에서 알 수 있듯 하나의 마스터, 하나 이상의 레플리카로 구성된 레디스 서버와 적어도 세개의 캐시 노드에서 작동하는 센티널로 구성된다.
센티널의 특징 중 하나는 여러 센티널 캐시 노드가 특정 노드를 사용할 수 없다고 확인되면, 장애로 감지한다는 점이다.
즉, 센티널 노드는 마스터와 레플리카를 감시하는 역할을 한다.
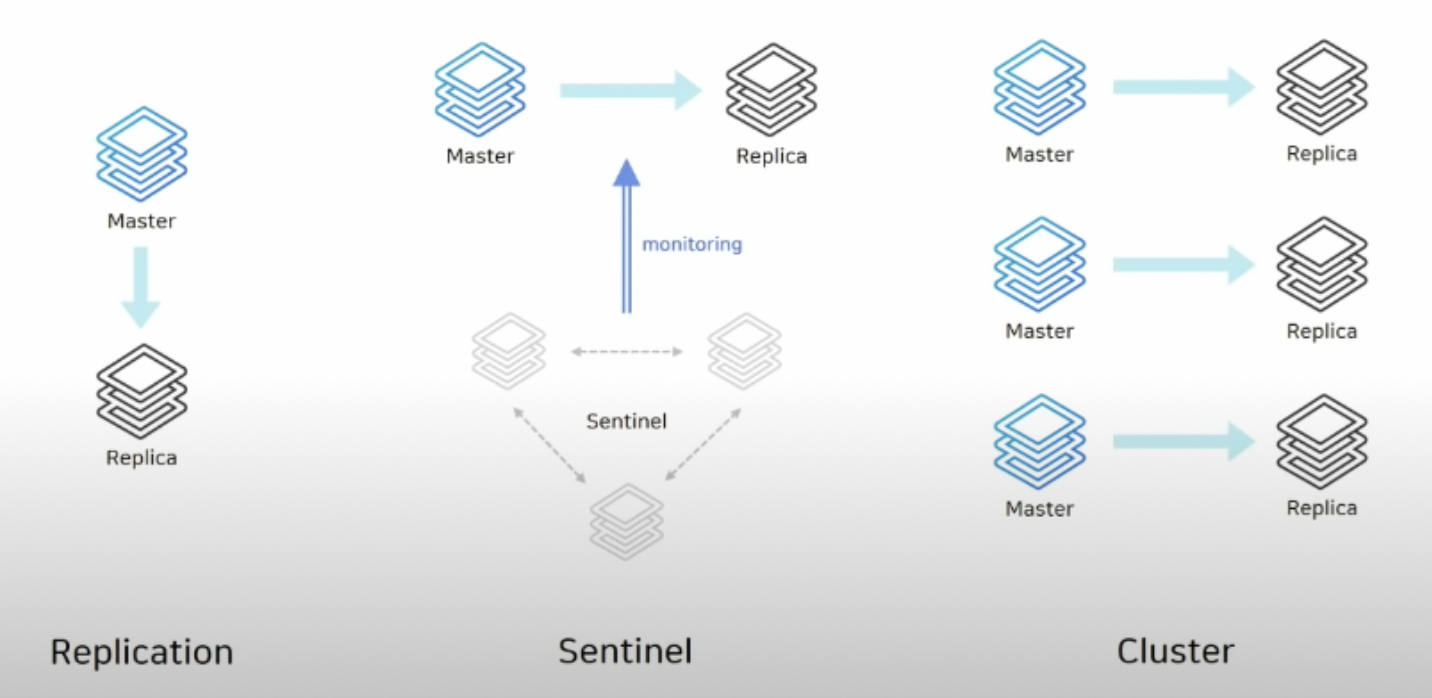
본 챕터에 나온 레플리케이션과 마지막에 간략히 업급된 센티널을 비롯해 레디스는 아래 3가지 아키텍처로 나누어서 볼 수 있다.
1. Replication: Master와 Replica로 구성
2. Sentinel: Sentinel, Master, Replica로 구성, 자동 Failover가 가능한 HA(High Availability) 구성
3. Cluster: 레디스 3.0 버전 이후부터 제공, 클러스터에 포함된 노드들이 서로 통신하는 구조
'Study OR Book > 실전 레디스' 카테고리의 다른 글
| [실전 레디스] Chaprter 10_클라우드에서 사용하는 레디스 (0) | 2025.07.21 |
|---|---|
| [실전 레디스] Chaprter 08_레디스 클러스터 (1) | 2025.07.14 |
| [실전 레디스] Chaprter 06_트러블 슈팅 (0) | 2025.07.01 |
| [실전 레디스] Chaprter 05_레디스 운용 관리 (0) | 2025.06.23 |
| [실전 레디스] Chaprter 04_레디스를 활용한 애플리케이션 작성 (0) | 2025.06.16 |



