
HikariCP는 Java 계열 애플리케이션에서 가장 널리 사용되고 있는 고성능 JDBC 커넥션 풀 라이브러리이다.
1. HikariCP 특징
- 성능 최적화: "zero-overhead" 철학을 기반으로 설계되어 매우 빠른 성능 제공
- 경량성: 라이브러리 크기가 작고(약 130KB) 런타임 오버헤드가 거의 없어 메모리 사용량이 적음
- 안정성: 커넥션 누수 감지, 자동 복구 메커니즘, 데드락 방지 등의 기능 제공하여 안정적인 데이터베이스 연결 보장
2. Spring Boot에서 사용되는 HikariCP
Spring Boot 2.0버전부터는 Tomcat JDBC 대신 Hikari를 사용하며 spring-boot-starter-data-jpa와 spring-boot-start-jdbc에 의존성이 포함되어 있다.
application.yml 예시
spring:
datasource:
hikari:
maximum-pool-size: 10
minimum-idle: 5
connection-timeout: 30000
idle-timeout: 600000
max-lifetime: 1800000
leak-detection-threshold: 60000
주요 설정 옵션
- maximum-pool-size: 풀에서 유지할 수 있는 최대 커넥션 수
- CPU 집약적 작업 위주: maximum-pool-size: 10 (CPU 코어 수와 비슷하게)
- I/O 대기가 많은 작업 (원격 API 호출 등): maximum-pool-size: 50 (더 크게 설정)
- minimum-idle: 풀에서 유지할 최소 유휴 커넥션 수
- connection-timeout: 커넥션을 얻기 위해 대기하는 최대 시간
- idle-timeout: 커넥션이 풀에서 유휴 상태로 유지되는 최대 시간
- max-lifetime: 커넥션의 최대 생존 시간
- leak-detection-threshold: 커넥션 누수 감지 임계값
3. Docker 환경에서 고려사항
컨테이너 환경에서는 리소스 제약을 고려하여 풀 크기 조정이 필요하다.
HikariCP의 공식 문서에 의하면,
1 connections = ((core_count) * 2) + effective_spindle_count) 즉, CPU 코어 수 * 2 + 디스크 수 정도의 설정이 권장된다.
코어 수는 당연히 현재 사용하는 서버 환경에서의 CPU 개수를 의미한다.
코어 수 * 2가 되는 이유는 Context Switching과 Disk I/O 때문이다.
디스크 수는 기본적으로 DB 서버가 관리할 수 있는 동시 I/O를 의미한다.
- 하드 디스크 1개가 spindle(저장장치 단위) 1개를 갖는다.
- 디스크가 16개 있는 경우 시스템이 동시에 처리할 수 있는 I/O 요청도 16개가 된다.
4. Connection Pool 이란?
데이터베이스 연결을 미리 생성해서 풀(Pool)에 저장해두고, 필요할 때마다 재사용하는 메커니즘이다.
왜 필요한가?
- 데이터베이스 연결 생성/해제하는 비용이 많이 드는 작업
- 매번 새로운 연결을 생성하면 성능 저하 이슈
- 동시 사용자가 많을 때 데이터베이스 서버에 과부화 가능성 있음
동작방식
웹 컨테이너가 실행될 때 미리 생성된 연결들을 커넥션 풀에 보관하고, 요청 시 연결을 대여 및 반납한다.
1) HikariCP는 미리 connection을 pool에 담아둔다.
2) 요청이 들어오면 Thread가 pool을 요청한다.
3) HikariCP는 connection을 제공한다.

5. DataSource 란?
데이터베이스 연결을 얻기 위한 표준 인터페이스
역할
- 데이터베이스 연결 정보 캡슐화
- Connection 객체를 제공하는 팩토리 역할
- JNDI 룩업, 커넥션 풀링 등의 기능 추상화
기본적인 DataSource 구현체
1) 풀링 없는 경우의 문제점
- 연결 생성: 네트워크 handshare, 인증, 세션 초기화 등으로 시간이 오래 걸림
- 연결 종료: 리소스 정리 작업으로 시간 소모
- 데이터베이스 서버에 부하 증가
2) 풀링의 동작 과정
(1) 애플리케이션 시작 시: 미리 정해진 수만큼 DB 연결을 생성해서 풀에 저장
(2) 연결 요청 시: 풀에서 사용 가능한 연결을 빌려줌
(3) 작업 완료 시: 연결을 풀로 반납 (실제 종료 x, 재사용 대기)
즉, HikariCP의 풀링은 연결 재사용 메커니즘을 의미한다.
// 1. 기본 DataSource (풀링 없음)
val basicDataSource = DriverManagerDataSource()
basicDataSource.setDriverClassName("com.mysql.cj.jdbc.Driver")
basicDataSource.url = "jdbc:mysql://localhost:3306/mydb"
// 2. HikariCP DataSource (풀링 있음)
val hikariConfig = HikariConfig()
hikariConfig.jdbcUrl = "jdbc:mysql://localhost:3306/mydb"
val hikariDataSource = HikariDataSource(hikariConfig)
// 1. 기본 DataSource (풀링 없음): 매번 새로운 연결을 생성
fun executeQuery() {
val connection = DriverManager.getConnection(url, user, password) // 새 연결 생성 (비싸고 느림)
val statement = connection.createStatement()
val result = statement.executeQuery("SELECT * FROM users")
// ... 처리
connection.close() // 연결 완전히 종료
}
// 10번 호출하면 10번 연결 생성/종료 반복
// 2. HikariCP DataSource (풀링 있음): 애플리케이션 시작 시
val pool = HikariDataSource().apply {
// 미리 5개의 연결을 생성해서 풀에 보관
minimumIdle = 5
maximumPoolSize = 10
}
fun executeQuery() {
val connection = pool.connection // 풀에서 기존 연결을 빌려옴 (빠름!)
val statement = connection.createStatement()
val result = statement.executeQuery("SELECT * FROM users")
// ... 처리
connection.close() // 연결을 풀로 반납 (실제로는 종료되지 않음)
}
6. Hikari CP 동작원리

- Thread가 Connection을 요청하면 Connection Pool이 2,3,4 과정을 처리하고, 유휴 Connection이 있으면 반환한다.
- HikariCP: 이전에 사용했던 Connection이 존재할 경우 우선적으로 반환한다.

- 만약 사용 가능한 Connection이 없다면, HandOffQueue를 폴링하면서 다른 Thread가 Connection을 반납할 때까지 기다린다.
- 지정한 TimeOut 시간까지 대기하다가 시간이 만료되면 예외를 던진다.
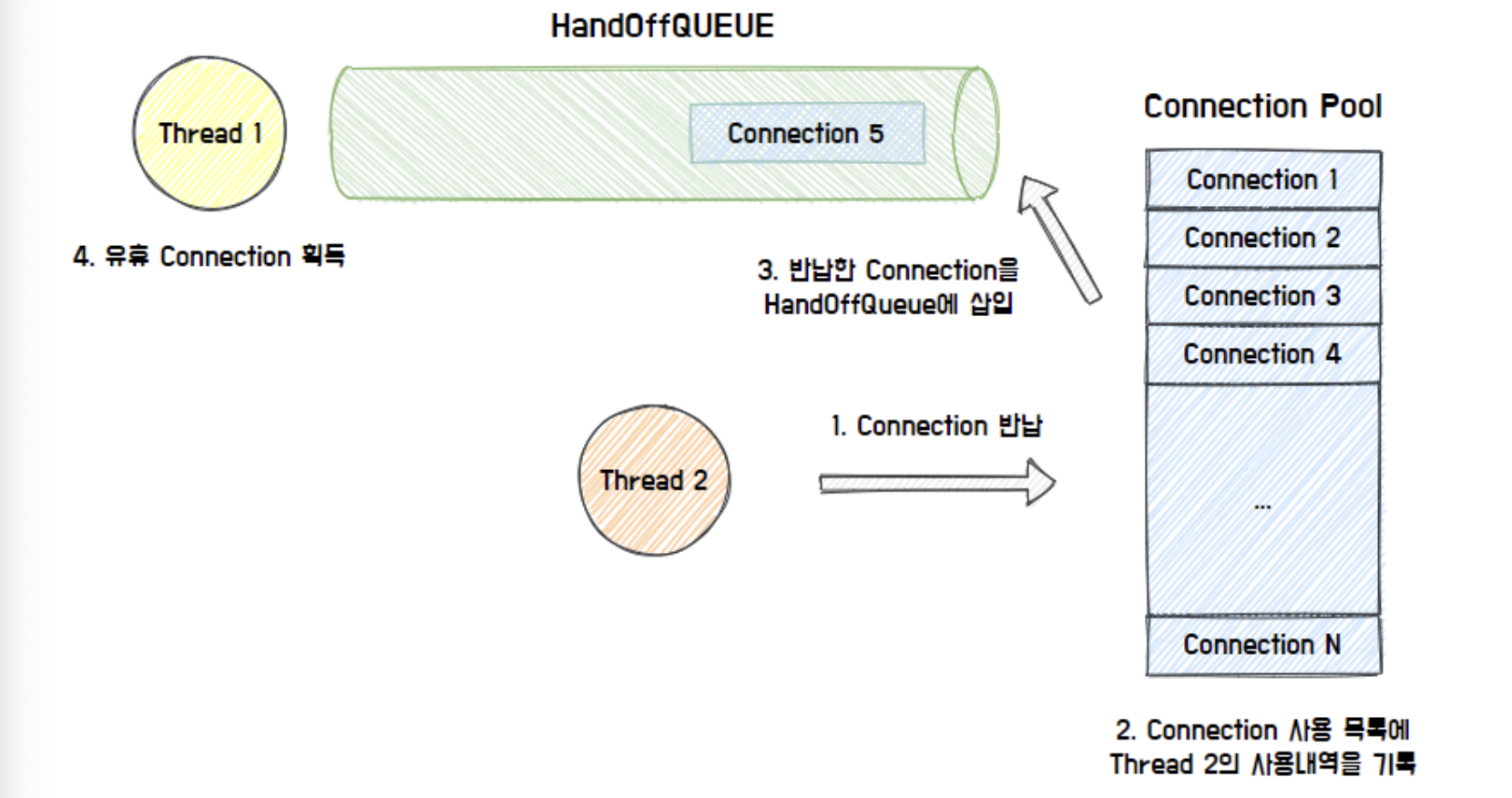
- 최종적으로 사용한 Connection을 반납하면 Connection Pool이 사용 내역을 기록하고, HandOffQueue에 반납된 Connection을 삽입한다.
- HandOffQueue를 폴링하던 Thread는 Connection을 획득하고 작업을 진행한다.
References
https://github.com/brettwooldridge/HikariCP?tab=readme-ov-file
https://devjjsjjj.tistory.com/entry/Connection-Pool%EC%9D%B4%EB%9E%80
'Computer Science > 개념 | 이론' 카테고리의 다른 글
| [JPA] OSIV (Open Session In View) (0) | 2025.07.18 |
|---|---|
| Forward Proxy VS Reverse Proxy (0) | 2025.02.26 |
